Your data might just keep your business alive
Mar 2, 2026

There's been a rather hilarious post doing the rounds recently, someone built a UI that looks and behaves almost identically to the Bloomberg Terminal using Claude Code, and the internet promptly declared that Bloomberg was "cooked." Which is a wonderfully dramatic response, and also almost entirely misses the point, especially that Linus even mentions this in his post… but it is a splendid example of how UI & data are two very different things to consider.
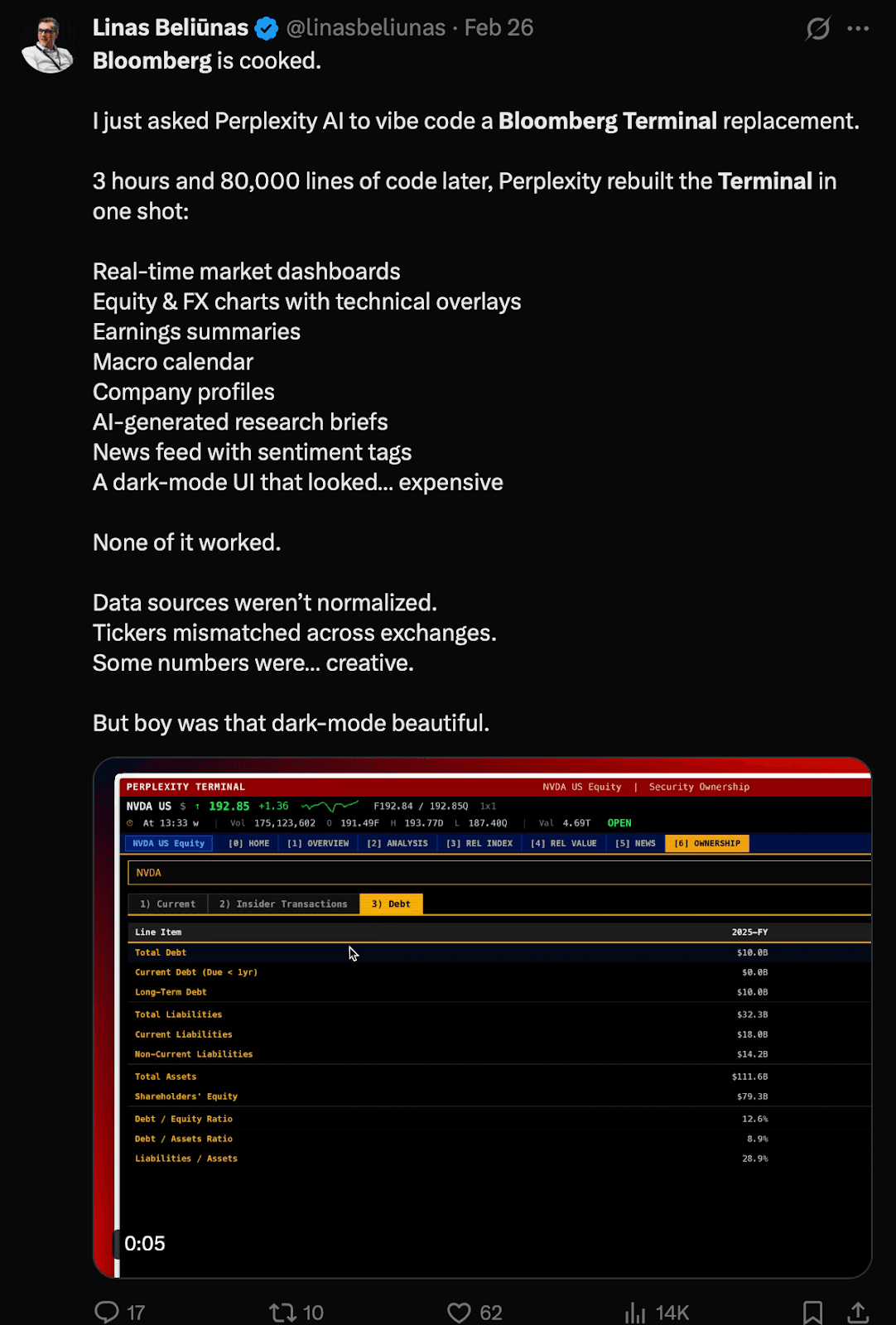
The Bloomberg Terminal costs somewhere in the region of £20,000 a year per user. For that, you get a dedicated machine, a keyboard, and access to an enormous breadth of financial data pulled from sources most people will never have direct relationships with. The reason serious financial institutions pay that without flinching isn't the interface, and it never was. It's the data behind it, who collected it, how it was verified, what it would cost to replicate, and whether you can actually trust it.
Copying the UI has always been possible, it just wasn't worth anyone's time before.
What AI has done is collapse the cost of building interfaces so dramatically that the UI is now essentially free. Which means anyone who was quietly relying on a complicated or expensive interface as their competitive moat has to be much more mindful about where the real value of their product is coming from.
Finance is a good place to see this clearly, partly because it keeps coming up in my work in a way that I find rather telling. I run training sessions for product, engineering and design professionals, and when I ask people to come up with genuinely new ideas, a remarkable number of them land on a new banking or finance app. They come in buzzing with UI concepts, beautiful flows, frictionless onboarding. The assumption underneath all of it is that the reason existing finance tools feel clunky and outdated is because nobody has bothered to design them properly yet.
Working with Lovey, an actual financial institution on the road to becoming a bank, I was responsible for rebuilding a chunk of their automated credit decisioning tool. And what that experience made very clear is that when you're dealing with a regulated financial product, the data doesn't sit behind the interface. It is the interface. Every integration we built, external credit checks, address verification, property and mortgage data, all of it had to be designed with the UI in mind from the start, because the data was what defined the constraints of what could actually appear on screen. You cannot design your way around the fact that, for example, Land Registry only serves data in a particular format or Experian will provide some personal data but not all, or that a credit decision requires a specific chain of checks before anything can proceed.
The people pitching beautiful new banking apps in my training sessions aren't wrong that the interfaces could be better. They're just looking at the symptom rather than the cause and the Bloomberg moment is really just that same misunderstanding playing out at scale.
The businesses that will be genuinely difficult to replicate are the ones sitting on data that can't easily be recreated, data that came from the real world, was collected by humans with expertise, and has a chain of trust behind it that an algorithm simply cannot manufacture.
My uncle is a botanist. He spends a considerable amount of his time in the literal fields of Cornwall and the Isles of Scilly, recording and logging rare plants, their precise locations, their conditions, the specific context around where they're found. This is painstaking, often very damp work. It is also, in a quiet way, worth a great deal. Because you can ask an AI to describe a rare plant, and it will do so with tremendous confidence. But you cannot ask it to tell you that this specific specimen exists in this specific location, because that fact only exists because a human went there, looked at it, and wrote it down.
That kind of data can't be faked. It can be approximated, hallucinated, guessed at, but the genuine article is irreplaceable, and over time, as the volume of synthetic and scraped data online continues to swell, the trustworthiness of original, verifiable data is going to become significantly more valuable, not less.
There's a theory that's been floating around online communities for a few years now called the dead internet theory. The idea is that a significant and growing chunk of what we encounter online, the comments, the reviews, the forum posts, the engagement, is no longer generated by real people at all. It's bots, automated content farms, and manufactured interactions, and has been for longer than most people realise. It sounds conspiratorial until you spend any time looking at the volume of SEO-driven content, fake reviews, and engagement manipulation that exists at scale, and then it starts to feel rather less like a theory and rather more like a sign of things to come.
This matters enormously for AI, because the models being trained to power the next generation of products are largely being trained on this internet. The one that is, to an uncertain but sizeable degree, already pretty darn hollow and untrustworthy. So when people talk about AI confidently generating authoritative-sounding information, it's worth pausing to ask where that confidence actually came from, and whether the sources it learned from were any more trustworthy than a five-star review left by someone who has never actually purchased some quirky gizmo from China.
This is the part that gets missed in a lot of conversations about AI and the future of products. There's a great deal of attention on what AI can generate, and considerably less on the question of whether what already exists online was worth training on in the first place. Much of it is inaccurate, outdated, commercially motivated, or just wrong. The models are eating it regardless.
Which brings me to a slightly awkward irony I find myself sitting with. I write articles like this one to share what I know, build trust with people who might want to work with me, and demonstrate that I've spent years thinking carefully about these things. I'm aware, as I do it, that everything I publish openly is available to be ingested by the same systems I'm describing. My thinking, my frameworks, my hard-won observations from years of field research, all of it potentially becoming undifferentiated training data.
I don't have a clean resolution to that. But I do think it sharpens a question worth asking if you're building a product right now. What data does your business actually create or have access to, and is it the kind that could be replicated by someone with a sufficiently large GPU and a scraping budget? If not, if it comes from genuine human expertise, real-world observation, or relationships built over time, then that is almost certainly where your value lives.
Protect it accordingly.

